Structured Intelligence
Turn information from any source into structured, continuously compounding intelligence for your organization.

Extract structured data from any source
Financial statements, contracts, company websites, regulatory filings, third-party databases. Every source type has a specialized ingestion path. Every path produces the same output: typed, structured entities in your operational model. You define the extraction logic and the target schema.
Habitat processes documents visually, in full page context, handling the complex layouts that conventional parsers break on. Web sources are scraped, parsed, and structured through configurable extraction schemas your team defines per use case.
AI powers every stage. Vision models read document pages, language models classify content and map fields to your schema. Accuracy improves continuously as the system processes more of your data.
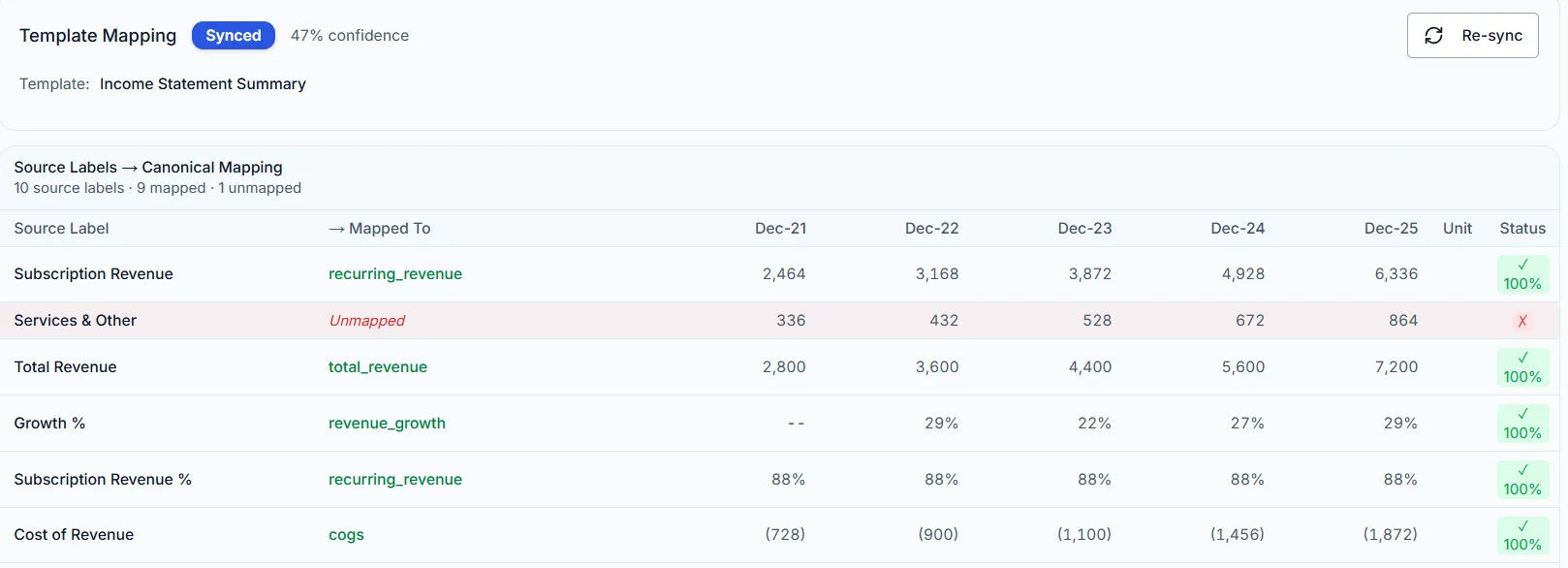
Financials template — structured extraction from investment documents
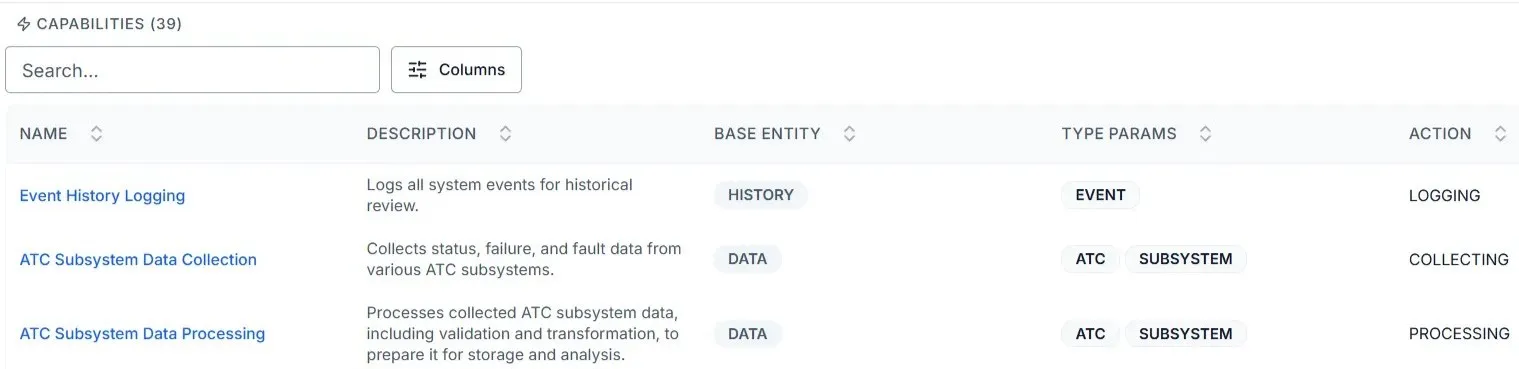
Product data — entity:action capability decomposition at scale
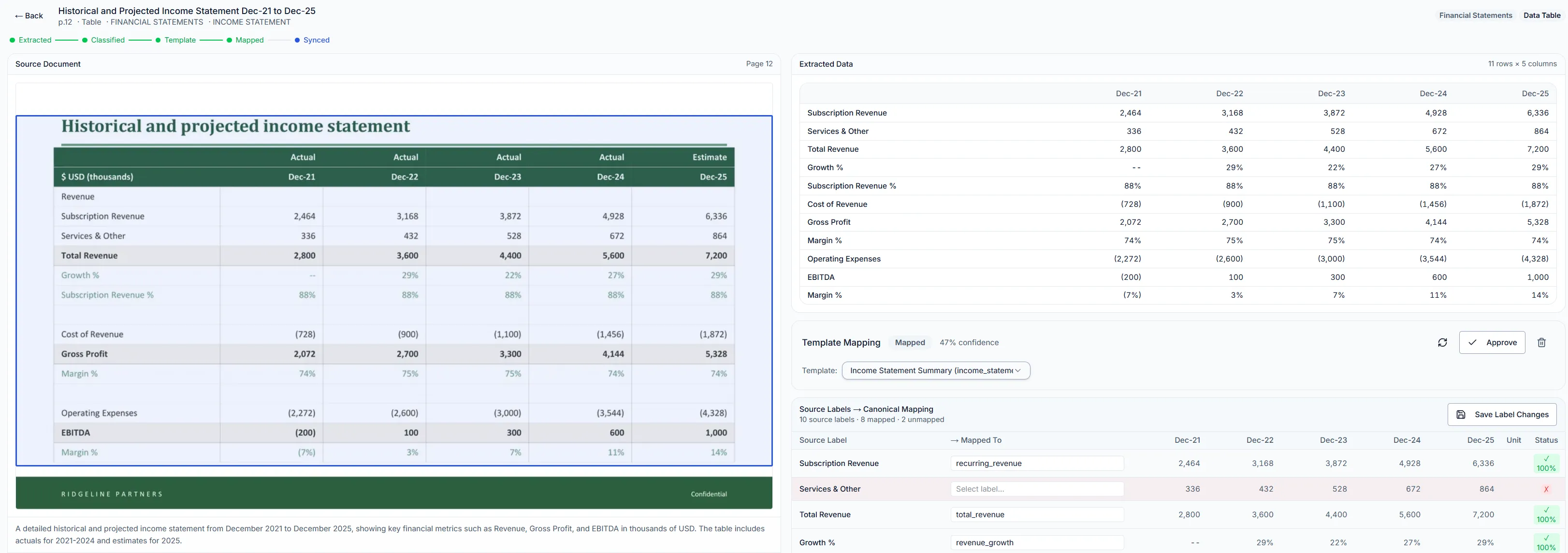
Every extracted value grounded to its source with bounding-box coordinates and confidence scores
Every value traceable to its source
Every extracted figure is grounded to its original location in the source document with bounding-box coordinates. A revenue number in a dashboard, a margin in a scoring rubric, a KPI cited in an AI response: each one links back to the exact page and the exact region it was extracted from.
Your analysts verify against the source in one click. The chain of evidence runs continuously, from raw document through structured entity through report through AI response. Provenance is built into the extraction from the first step.
Classify, compare, position
Structured intelligence enables analysis that raw data cannot support. Decompose entities into capabilities, map them to markets, compare competitive positioning across taxonomies, and surface patterns across hundreds of structured profiles.
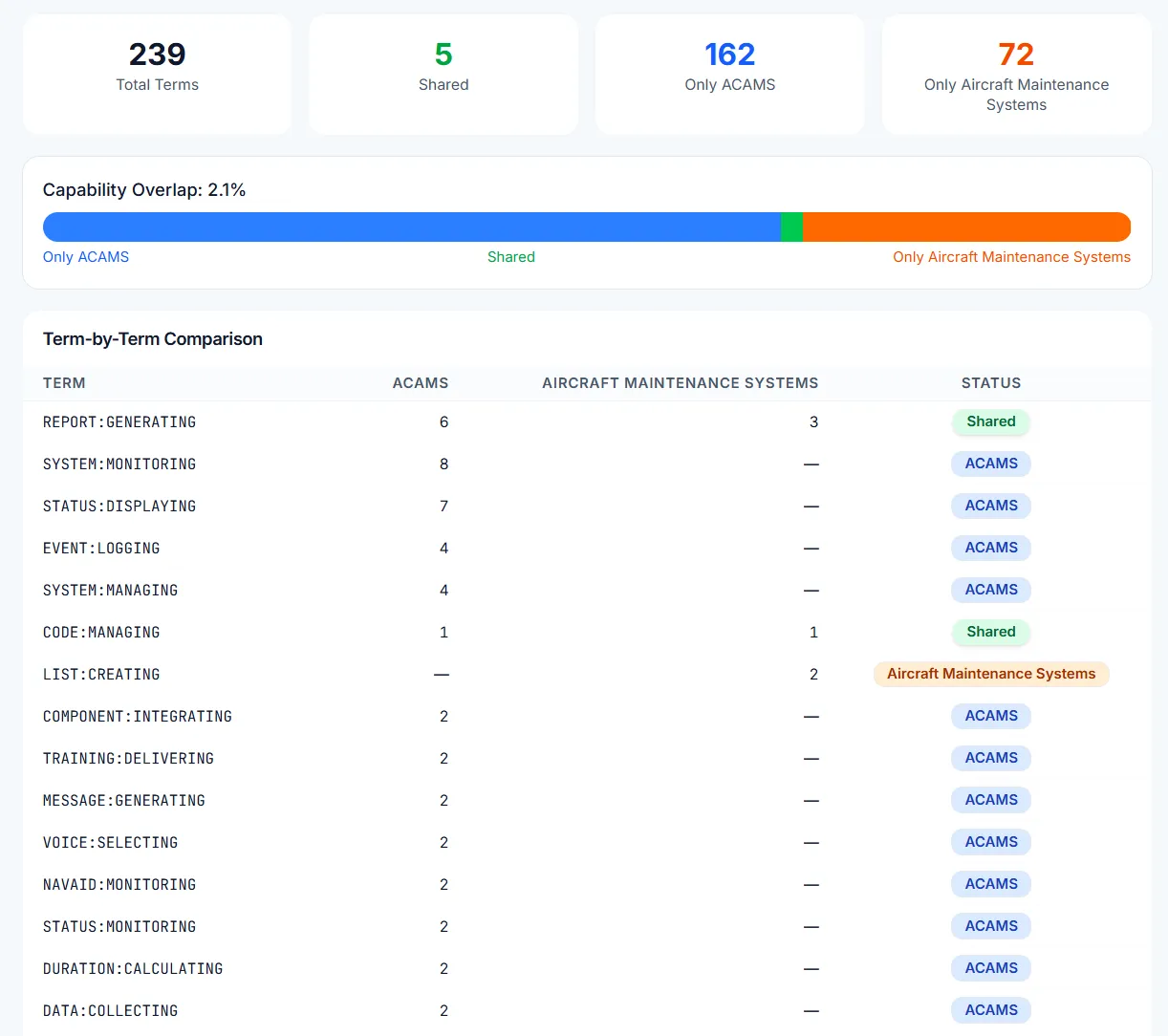
Term-by-term capability overlap analysis across structured taxonomies.
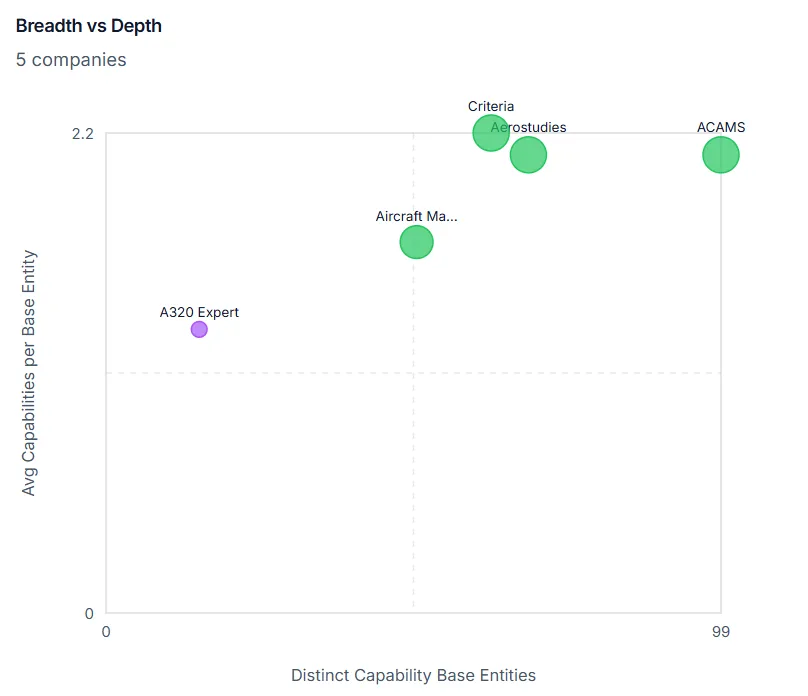
Breadth vs. depth positioning across your intelligence base.
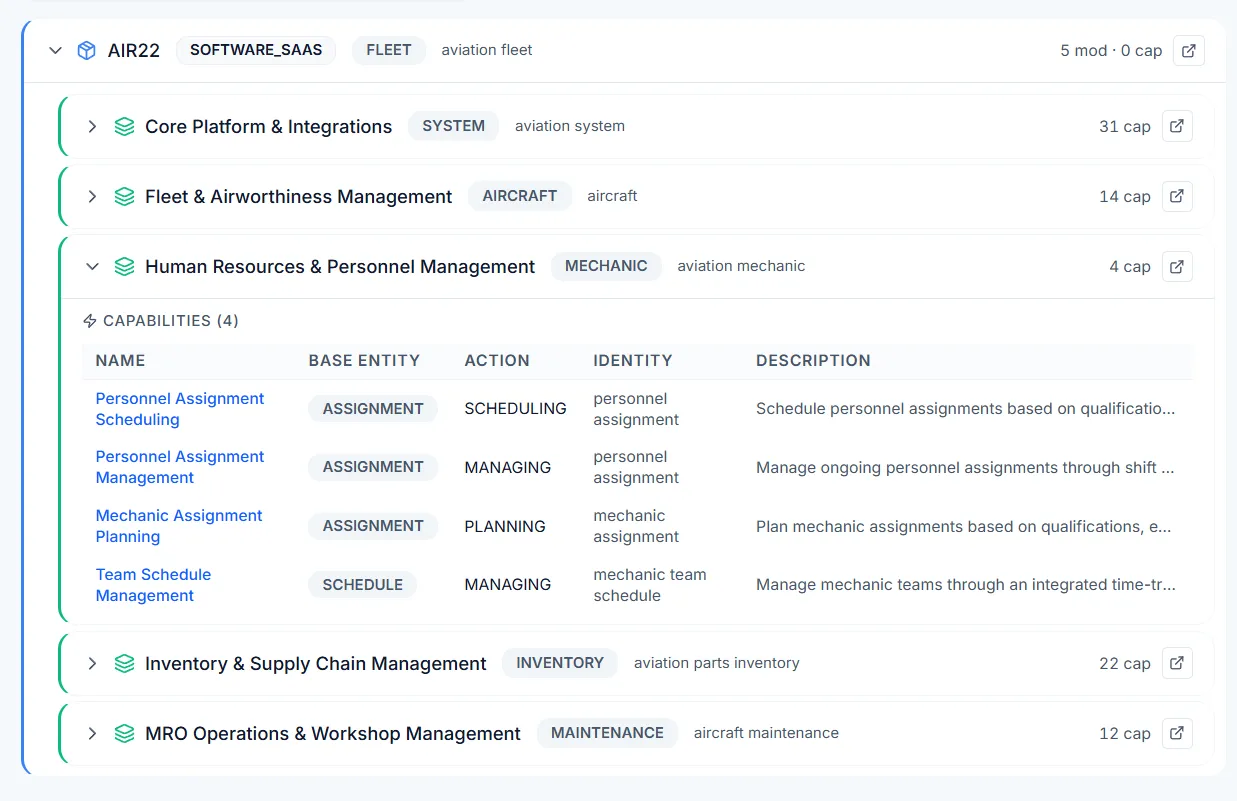
Full product-level decomposition with entity, action, and identity resolution.
Query it, report on it, score against it
The intelligence is captured once and operationalized everywhere.
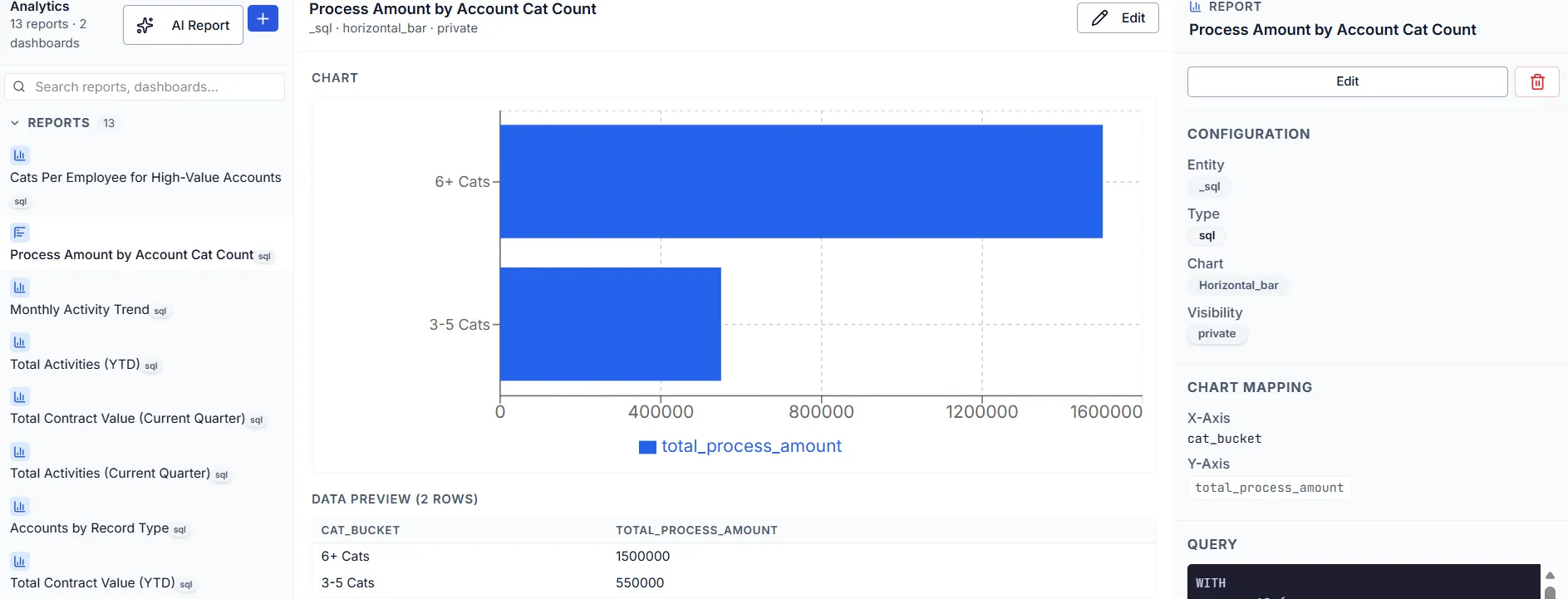
Reports and dashboards aggregate extracted metrics across a portfolio. Scoring rubrics evaluate against quantitative criteria. Comparative analyses surface patterns across hundreds of documents.
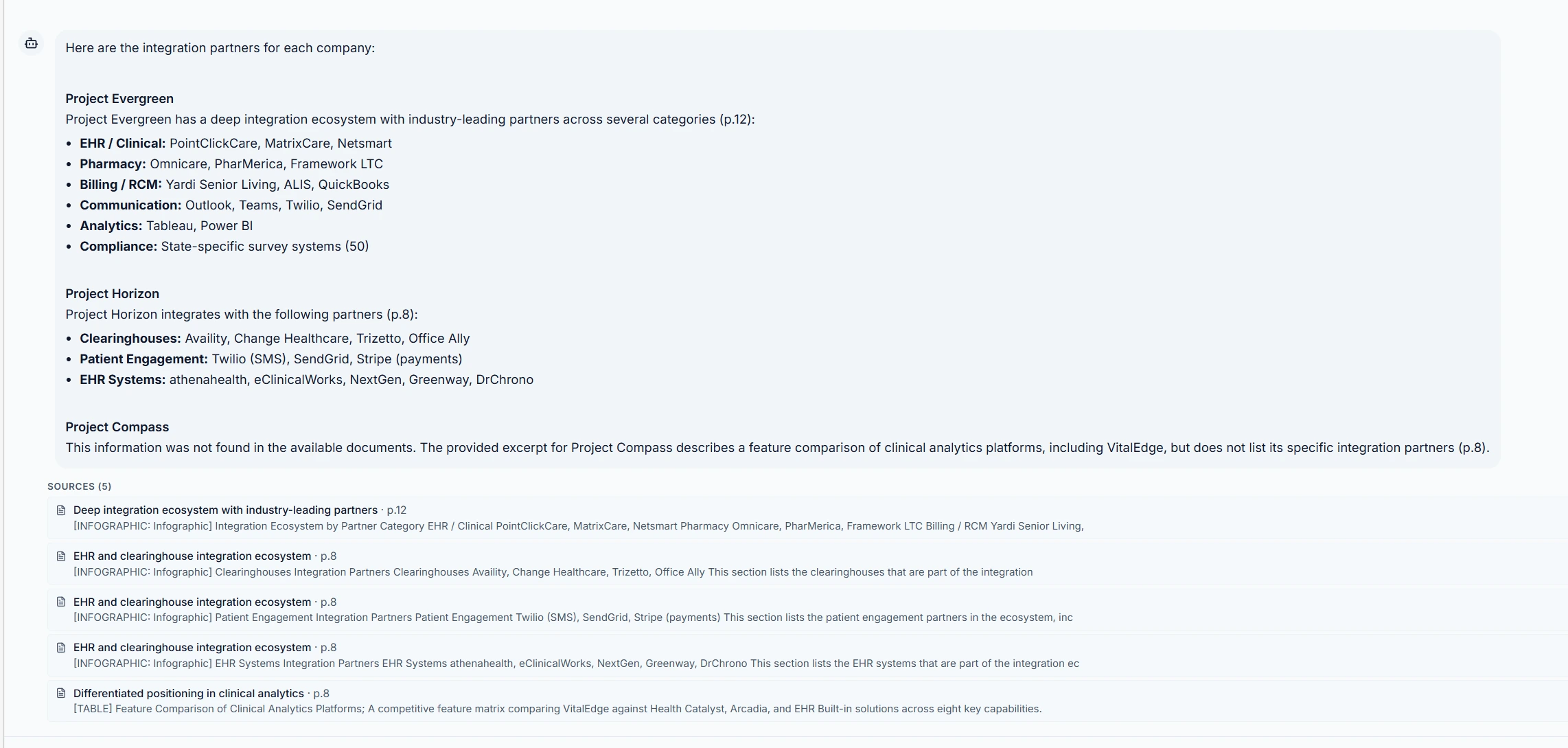
Ask a question, receive an answer grounded in your full document corpus with citations to the specific page and section. The same extraction, the same provenance chain.
Fine-tune with synthetic data
We analyze your actual data distribution, document formats, and classification patterns to identify the trends and classes that matter to your operations. From that analysis, we generate synthetic training data that mirrors your specific workflows and use it to fine-tune models that are swapped in per pipeline stage without changing any platform code.
Fine-tuning is fully optional. The platform operates with high accuracy on base models out of the box. Where fine-tuning applies, it drives two outcomes: higher extraction accuracy on your specific data, and lower inference costs by replacing large general-purpose models with smaller, specialized ones optimized for your domain.
See it in action
We'll walk you through how structured intelligence applies to your operations.