Sourcing at Scale: From Classification Algorithms to a 30M+ Company Universe
How proprietary classification algorithms and a multi-dimensional search engine solved the problem that every data product on the market failed to address — finding the companies that everyone else misses.

Sourcing methods and their trade-offs
Outbound sourcing is something that's near (but perhaps not so very dear) to the hearts of every investor. While all of these methods have their merits, we noticed that once a market got too competitive, or an investor wanted to scale up from several deals a year, most no longer gave them a cost effective way to support their growth.
| Method | Volume | % Success | Cost | Time | Competition | Scalability |
|---|---|---|---|---|---|---|
| Personal Connections | Low | High | Low – High | High | Low | Low |
| Broker Relationships | Low | Medium | High | Low | High | Medium |
| Events or Conferences | Low | Low | High | High | Medium | Low |
| Social Media | Low | Low – Med | Low | High | Low | Medium |
| Deal Marketplace | Medium | Medium | High | Low | High | Low |
| Data Products | High | Low | Medium | Medium | High | Medium |
| Manual Search | Medium | Low | Low | High | High | Low |
| Custom Lead Engine | High | Medium | Medium | Low | Low | High |
Why data-driven sourcing fails
The math looks great
Data product per year: $20K
Offshore resource per year: $10K–15K
Leads per resource (optimistic): 10K/year
With 0.01% lead-to-close: 1 deal/year = $35K per deal. 5 resources = 5 deals at $19K each.
The reality check
• All your competitors will buy the same data products
• Everyone will find the easiest 50% of companies by utilizing industry filters, simple keyword search, or AI recommendations
• Everyone contacts the same companies and increases the probability of a brokered process
• Low-cost resources mean you fill your database with junk
• Anything proprietary you find, you expose to competitors through CRM sync/integration
That doesn't mean data-driven sourcing can't be successful — it just needs to be done in a thoughtful, proprietary, and custom way.
Why existing data products fall short
As we explored various data products, we encountered the same issues with every product on the market.
Poor classification
Most data products do not differentiate between vertical software and regular software. Of companies classified as 'Software' or 'IT', only 6–7% can be considered vertical software.
Poor global coverage
Especially poor coverage of companies based outside of North America, which we attributed to the language barrier.
Limited market research
Many products only offer limited exports. Poor industry classification exacerbates the issue — you can't pull 'Healthcare Software in Canada' without cross-referencing multiple filters.
All in all, we did not have a good time with this experience — a sentiment shared by essentially every M&A employee that is on the ground and actually dealing with this exercise on a daily basis.
Proprietary classification at scale
The foundation for every company intelligence product on the market tends to be built from some combination of three major data sources: LinkedIn company profiles, government company registries, and company website data.
We leveraged all of these sources (and many others), multiple sourcing methodologies, and a set of proprietary classification algorithms to extract relevant companies from a universe of tens of millions.
Multi-dimensional search
A multi-dimensional search algorithm with weighted scoring across keywords, descriptions, and full-text content. IDF normalization, phrase specificity bonuses, and keyword expansion.
Proprietary classification
Classification algorithms that go beyond industry codes — parsing product descriptions, feature sets, and company positioning to identify companies that generic filters miss.
Generative AI scoring
AI-powered re-ranking and validation against your specific investment mandate, considering any factor you define.
Analyst validation
Every company validated by an analyst — resulting in higher relevance than any data product on the market.
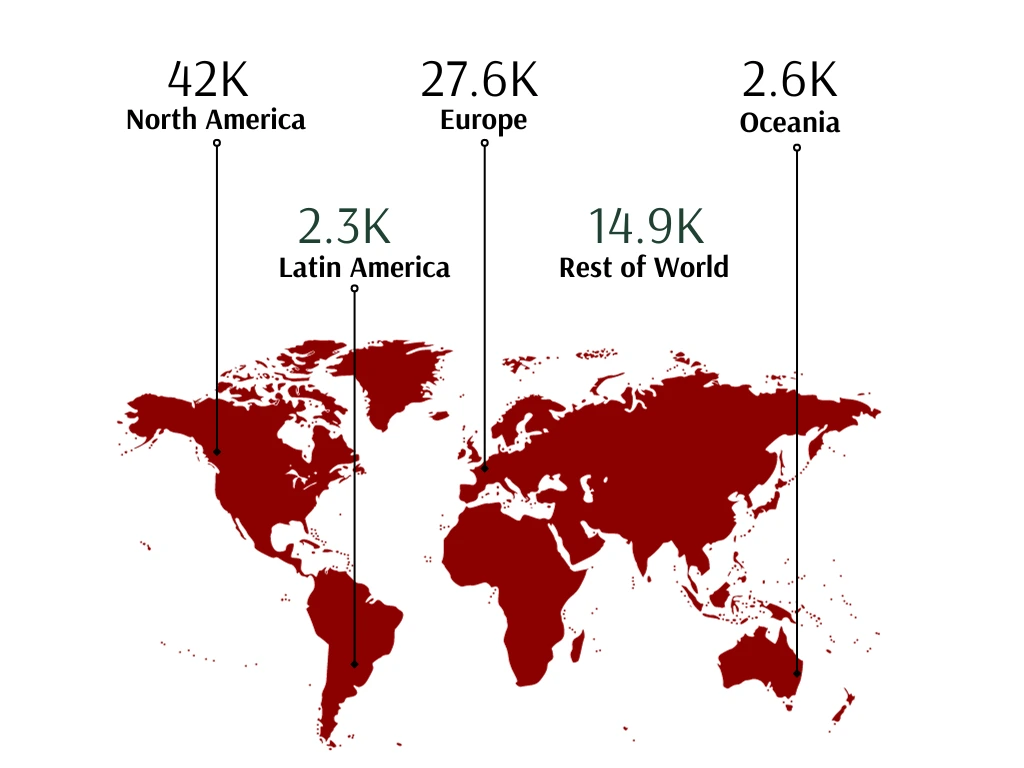
The platform does not discriminate by geography or language — almost 40% of companies are sourced from Europe, with an emerging presence in Latin America.
From Kiosk to a general-purpose sourcing engine
The methodology was first proven with Kiosk — a vertical market software data platform built for investors. Notoriously tedious to identify and often misclassified by traditional data products, vertical software companies had eluded all but the most resourceful investors.
Kiosk extracted over 85,000 vertical software companies from a universe of 13M companies using proprietary classification. By 2025, the platform had expanded to cover over 200,000 verified software companies and had become a core part of the sourcing process for dozens of international investors headquartered in seven countries.
The algorithms and methodologies that powered Kiosk became the foundation for a general-purpose sourcing engine. The same classification pipeline now processes 30M+ companies and can be configured for any industry, any mandate, and any geography.
200K+
Verified software companies on the platform
73
Industries with precise sub-classifications
24
Average functional keywords per company
7
Countries with active institutional users
Your own sourcing engine
• Same data products as competitors
• Focus on easiest 50% of companies
• High competition for same targets
• Low-quality leads and database pollution
• Data sharing exposes proprietary findings
• Fully customizable industry taxonomy from a universe of 30M+ companies
• As close to 100% coverage of any geography or vertical as you need
• Insight into, and ability to customize, proprietary classification algorithms
• Fresh contact data and financial data where available
• Completely proprietary and confidential
75%
Improved market coverage over traditional data products
30M+
Active companies in the sourcing universe
3x
Higher lead quality through proprietary classification
More insights

From CRM Chaos to Investment Intelligence
How a billion-dollar software investor transformed their M&A operations in 30 days
CRM
Investment Strategy Framework
A three-sphere framework for data-driven M&A decision making
Strategy
Data for M&A Operations
Building data infrastructure across the full investment lifecycle
DataBuild your own sourcing engine
Tell us about your mandate. We'll show you what proprietary sourcing looks like for your industry and geography.